|
Xiaolong Huang |

|
Research |
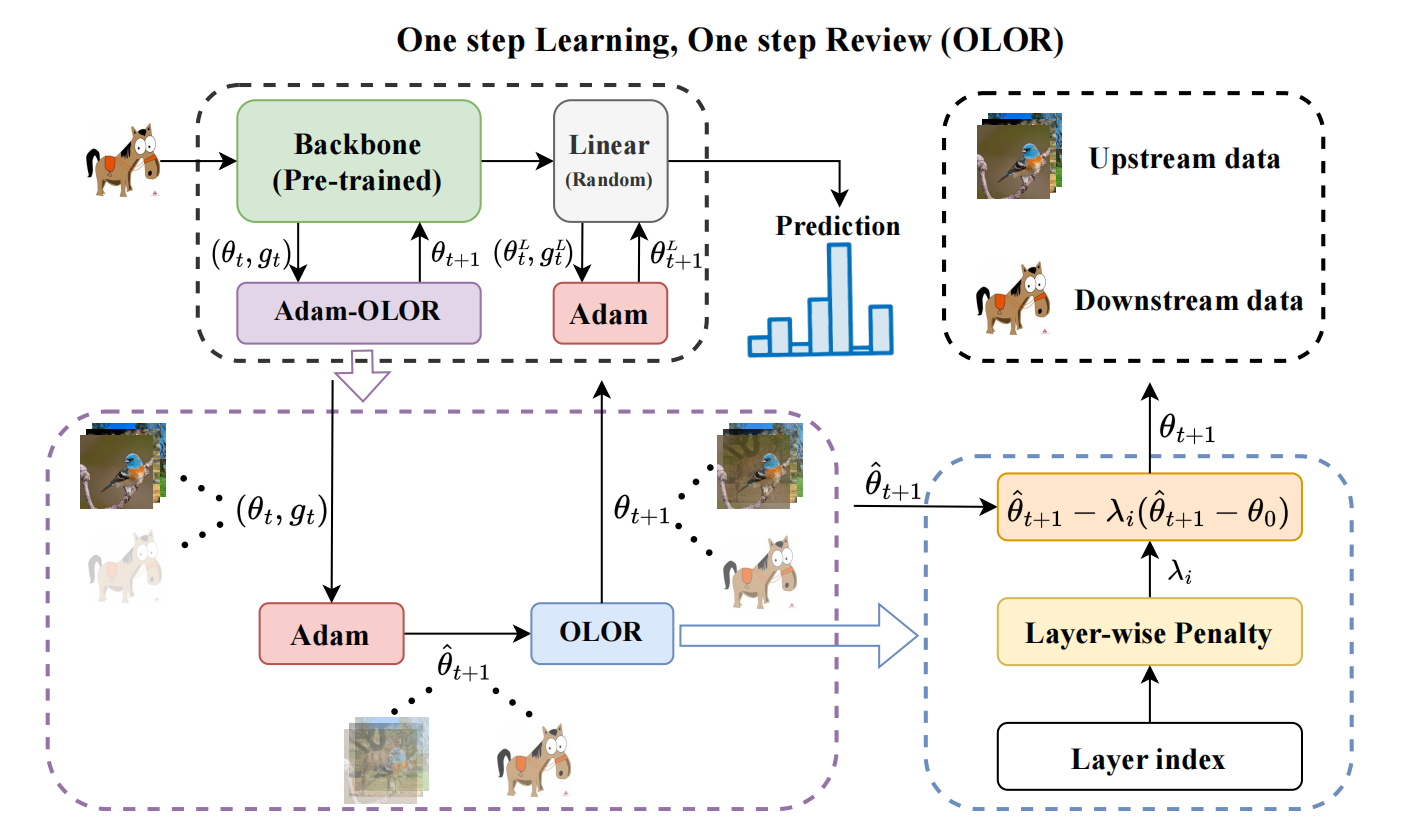 |
Xiaolong Huang, Qiankun Li, Xueran Li, Xuesong Gao AAAI, 2024 paper / webpage / arXiv |
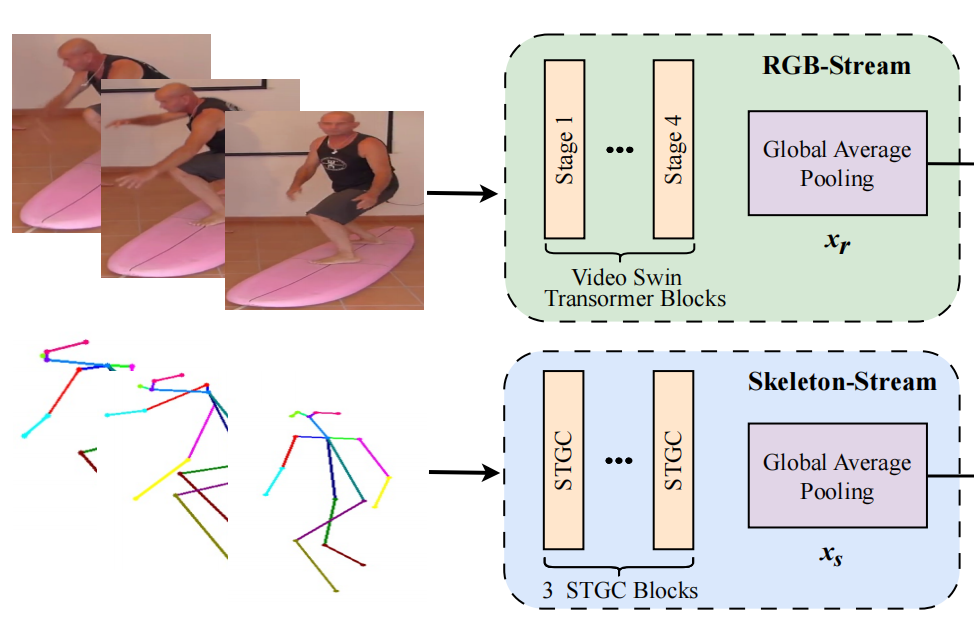 |
Qiankun Li, Xiaolong Huang, Yuwen Luo, Xiaoyu Hu, Xinyu Sun, Zengfu Wang AMC-SME Workshop, ACMMM, 2023 webpage |
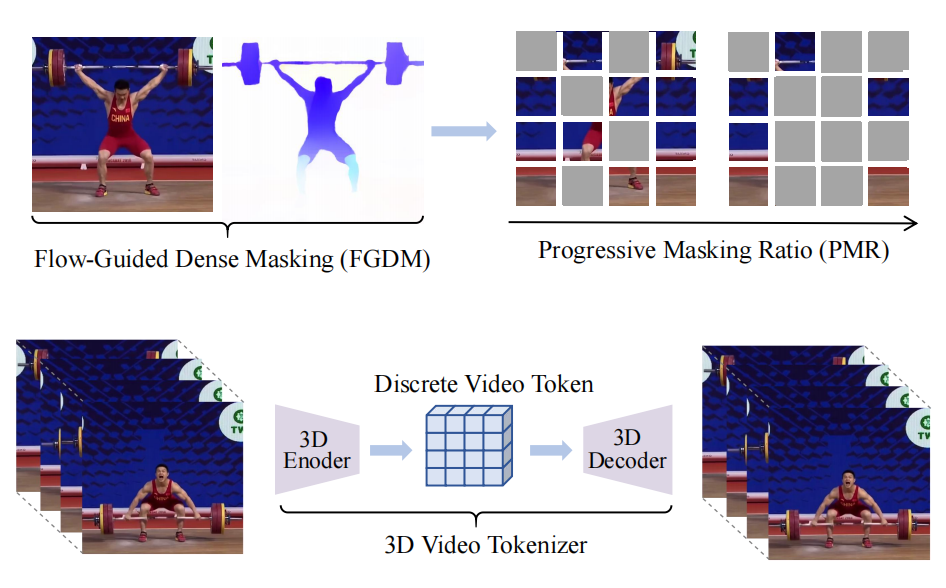 |
Qiankun Li, Xiaolong Huang, Zhifan Wan, Lanqing Hu, Shuzhe Wu, Jie Zhang, Shiguang Shan, Zengfu Wang ACMMM, 2023 webpage |
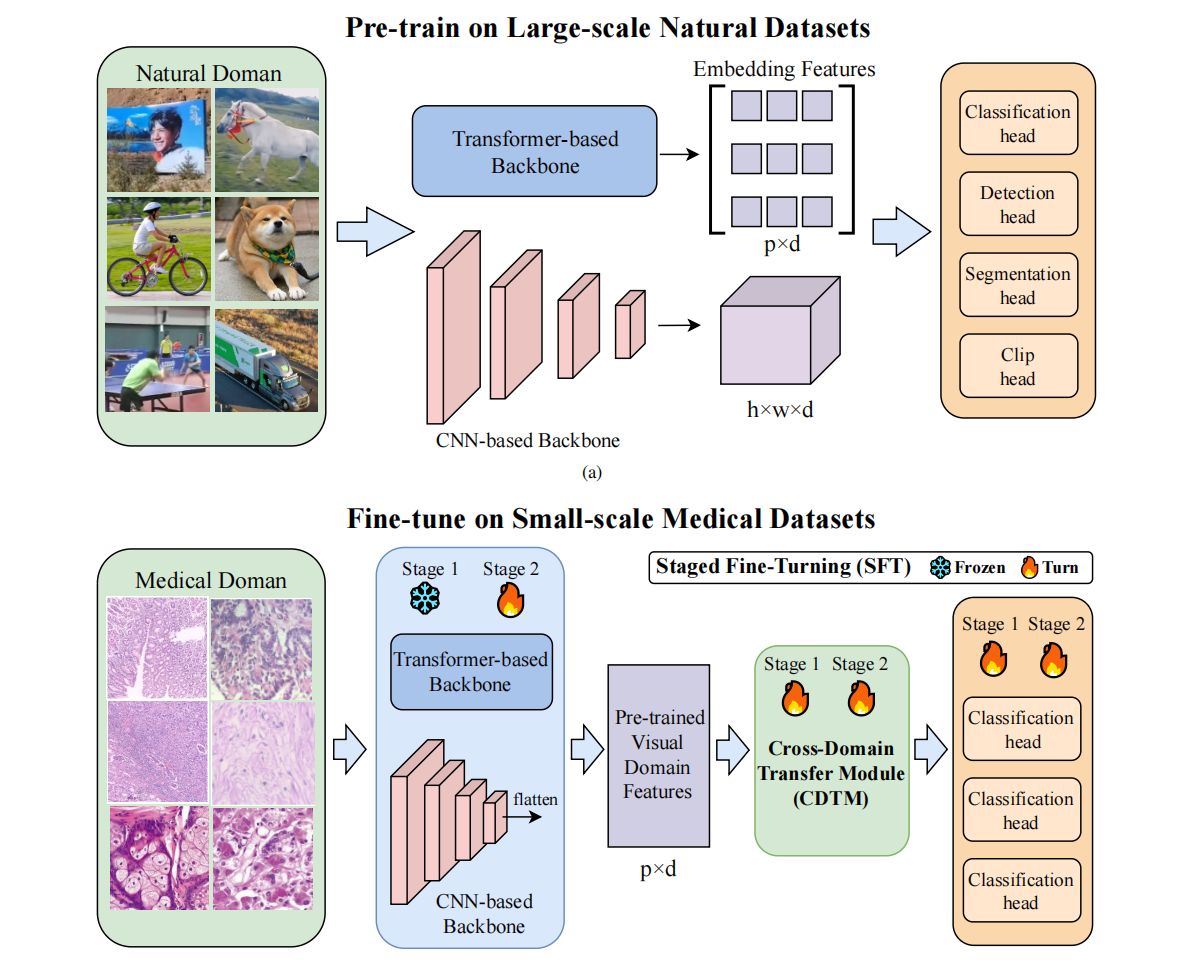 |
Qiankun Li, Xiaolong Huang, Bo Fang, Huabao Chen, Siyuan Ding, Xu Liu JBHI, 2023 webpage |
 |
Xiaolong Huang, Qiankun Li ILR Workshop, ECCV, 2022 paper / arXiv |
|
Folked from Jon Barron's website. |